df 라는 변수 안에 pd.read_csv 넣어줌뒤에서 부터 n 개일 때에는 tail() 함수 사용
데이터 프레임과 시리즈
(시리즈는 줄글 데이터 프레임은 표 모양)
시리즈는 [] 사용, 프레임은 {} 사용
({}) 순 임을 기억하기 데이터 프레임과 데이터 시리즈는 다름!!
데이터 프레임 만드는 함수 pd.DataFrame ({"칼럼명" : 데이터})
데이터 프레임 만드는 방법은 외우기
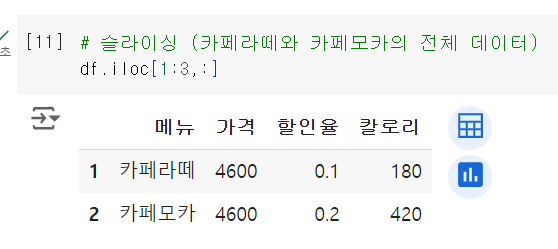
nunique() 함수는 항목의 개수자료형 변환 nan과 같은 결측치 사용할 때에눈 import numpy as np 사용할 것!df = df.drop(1, axis=0) 이라고 df 라는 변수에 대입을 해줘야 함, 그렇지 않으면 그냥 삭제만 하는거임loc[행, 열] , 열은 컬럼명으로 작성해도 됨loc와 iloc 다름, iloc 는 앞에 행 인덱스 번호이나 포함 안함, 뒤에는 컬럼 번호이나 포함함
sorting
인덱스 기준 sort_index두 개로 sort 하는 거면 () 안에 []로 묶어주기
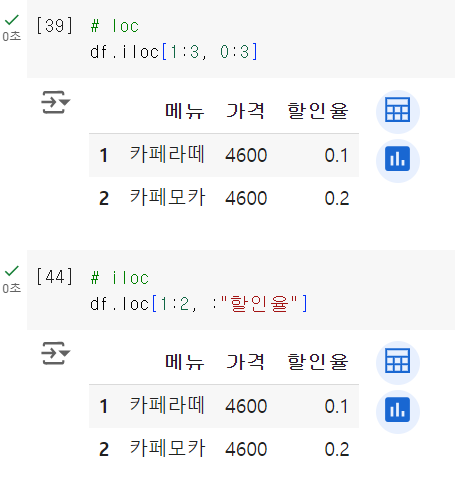
loc는 마지막 값을 포함하고, iloc는 마지막 값을 포함하지 않음
iloc는 실제 라벨과 무관하게 위치 기반한다. iloc는 무관하다!df[] 안에 값을 넣어주기도 함!
결측치 채우기
fillna() 괄호 안에 결측치 값을 넣어주면 됨loc [] 안에 '원두' 라고 넣어준 거는 표의 열값이 원두 이기 때문임!! 인덱스값이 아니잖아~
내장함수
quantile() 안에 소괄호, 최빈값 구하는 함수는 mode()[0] 임!!quantile(.75) = 상위 25%에 해당하는 값임
그룹핑 함수 groupby()
데이터프레임 형태로 만들기 위해서는 pd.DataFrame()으로감싸주면 됨가격이 5000 이상이려면 일단 cond라는 조건을 지정한 뒤에 len에 감싸주면 됨 len(df[cond[) 라고 지정하기!